AI-powered SKU Normalization Pipeline for E-commerce Operations

Product team
1 backend engineer
1 AI / data-focused engineer
QA support during the validation phase
Duration: 12 months
Technologies
Laravel
OpenAI API
PostgreSQL
Redis
Laravel Horizon
Production Context
Managing product data at scale across multiple suppliers and marketplaces is inherently inconsistent.
SKU titles and attributes vary in structure, language, units, and completeness, making manual normalization impractical and error-prone. Poorly normalized data directly affects search quality, analytics accuracy, catalog consistency, and downstream system integrations.
About Project
The project is an AI-powered data normalization pipeline designed to process large volumes of raw product data from multiple suppliers and marketplaces under real-world conditions.
Its primary goal is to transform inconsistent, noisy SKU titles and attributes into a unified, structured, and machine-readable format suitable for analytics, search, catalog management, and downstream integrations.
Core Capabilities
AI-based SKU normalization
Automatic extraction of structured fields (brand, units, quantity, category) from unstructured product titles and attributes using LLM-powered parsing with deterministic output rules.
Strict data consistency & validation
Enforced JSON schemas, rule-based constraints, and validation layers to guarantee predictable and auditable results.
Unit conversion & standardization
Intelligent normalization of measurement units (weights, volumes, counts) into a single standardized format across all products.
Batch & background processing
High-volume SKU processing using queued jobs and batch workflows without blocking core system operations.
Quality control & fallback logic
Automatic re-processing, fallback strategies, and result auditing for edge cases or low-confidence outputs.
Scalable job orchestration
Queue-based execution with retries, timeouts, error handling, and real-time monitoring.
Audit-ready results storage
Normalized data, intermediate states, and AI outputs are stored for traceability and future analysis.
The Process
Discovery & data analysis
Incoming product feeds from multiple sources were analyzed to identify recurring inconsistencies in SKU naming, units, categorization, and structure. This analysis defined normalization rules, quality benchmarks, and strict output contracts.
Architecture & prompt design
A background-first architecture was designed around queued jobs and batch processing. Special attention was given to prompt constraints, schema validation, and deterministic output rules to ensure AI behavior suitable for production use.
Development & iteration
The pipeline was implemented using Laravel jobs and batch workflows with Redis-backed queues and Horizon for observability. Multiple iterations were required to improve accuracy, handle edge cases, and optimize throughput under load.
Quality control & optimization
Fallback logic, re-processing flows, and auditing mechanisms were introduced to maintain high data quality. Performance optimizations ensured stable processing of large SKU batches at scale.
Result
The resulting pipeline became a reliable foundation for large-scale SKU normalization across multiple suppliers and marketplaces.
The system enabled:
- Consistent, structured product data across heterogeneous sources
- Reduced manual normalization effort and data cleanup
- Improved search relevance and catalog consistency
- Reliable downstream analytics and integrations
- Safe, auditable AI-assisted processing suitable for production environments
The architecture proved scalable under high SKU volumes and resilient to data variability and edge cases.

Start creating something
exceptional together!
More recent Case Studies

Seamless LMS platform for interactive math education
A multi-tenant LMS platform for interactive arithmetic education that combines engaging, child-friendly learning experiences with structured learning flows and progress tracking. The system provides educational organizations with the tools to manage courses, classes, and users while maintaining full administrative control across multiple organizations.

Booking & E-commerce platform for beauty service providers
A booking and e-commerce platform built for real-world beauty service operations, combining reliable appointment scheduling with integrated product sales. The system ensures consistent availability, structured booking flows, and operational control while delivering a fast, mobile-friendly experience for clients.
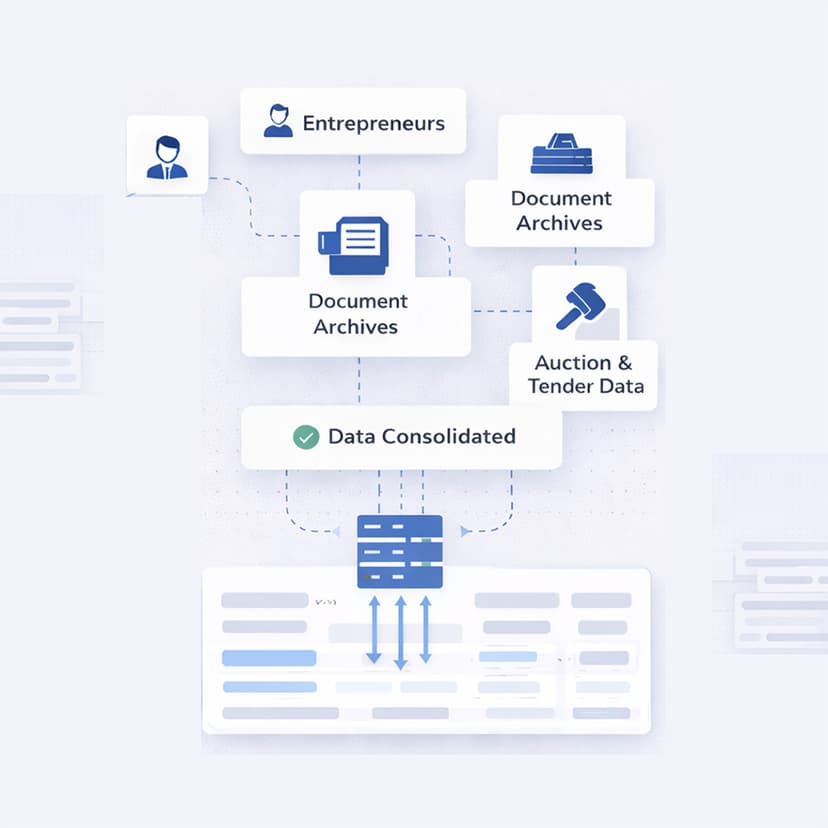
Open Data Aggregation Service for Entrepreneurs, Legal Entities & Tenders
An open data aggregation service that consolidates multiple public registries into a unified, searchable platform. The system normalizes heterogeneous datasets, preserves data provenance and update history, and enables reliable cross-linking between entrepreneurs, legal entities, and related tenders.
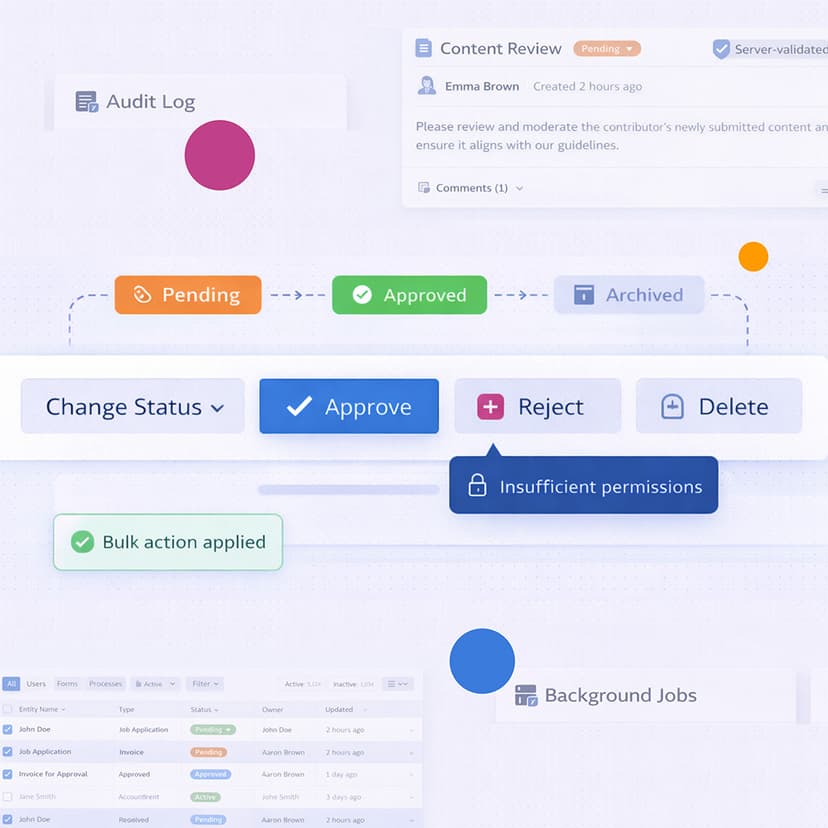
Admin Panels & Backoffice Suite for Internal Operations
A permission-driven admin and backoffice suite built for high-risk internal operations, where control, safety, and auditability are critical. The system enforces business rules server-side, supports role-based workflows, and provides clear visibility into actions, statuses, and execution history.
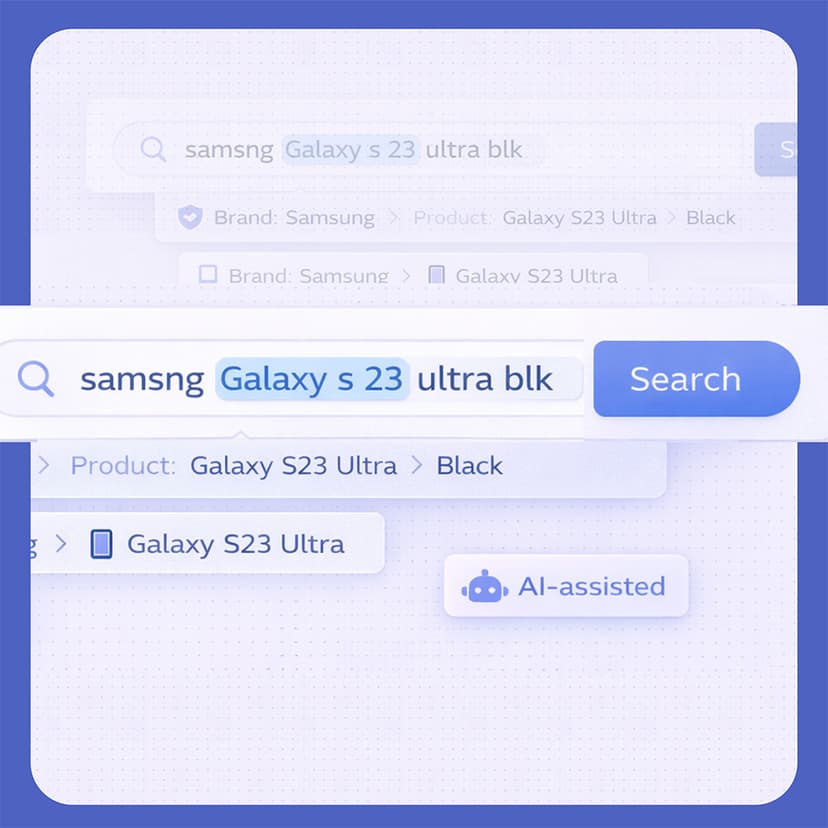
Smart Search System with AI-assisted Query Understanding
A smart search system built for real-world free-text queries, combining deterministic relevance modeling with AI-assisted query understanding. The solution handles typos, fuzzy matches, and mixed-language input while maintaining predictable behavior, stable relevance, and high performance at scale.
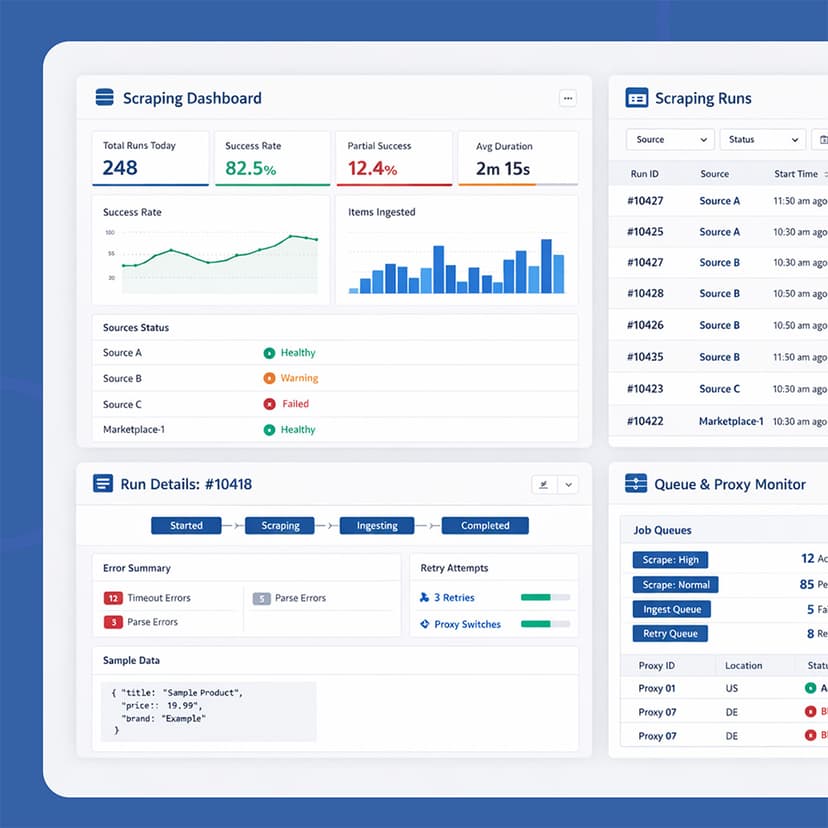
Retail Scraping & Ingestion System for E-commerce Data Collection
The system is designed for reliable extraction and ingestion of e-commerce product and promotional data. It supports multiple pagination strategies, operates through a managed proxy pool, and ensures stable data collection at scale. The goal is to provide consistent, observable, and fault-tolerant retail data pipelines.
Custom SaaS CRM for E-commerce Operations
A custom SaaS CRM platform built for centralized order management, operational automation, and fulfillment workflows. The system integrates with WordPress-based e-commerce websites, synchronizes incoming orders, and helps operational teams manage the full order lifecycle from creation to shipment within a single platform.