Open Data Aggregation Service for Entrepreneurs, Legal Entities & Tenders

Product team
1 backend engineer
1 data-focused engineer
QA support during validation phase
Duration: 9 months
Technologies
Laravel
MongoDB
Redis
Blade / HTML
Alpine.js
Laravel Horizon
Problem Overview
Working with public open data related to entrepreneurs, legal entities, and tenders required aggregating information from multiple registries with different data structures, formats, and update cycles. These datasets were fragmented, inconsistent, and difficult to analyze in a unified way.
The absence of a centralized system made it challenging to:
- Search and filter data efficiently across multiple registries
- Cross-link entrepreneurs, legal entities, and related tenders or auctions
- Track data freshness, source attribution, and historical changes
- Adapt quickly to frequent schema and format changes in public registries
Traditional approaches based on rigid relational schemas proved insufficient for handling the variability and continuous evolution of open data sources at scale.
Our Role
We were responsible for the full-cycle design and development of the system — from data model definition and ingestion architecture to storage, search optimization, and administrative interfaces.
Solution
We designed and implemented an open data aggregation service that collects, normalizes, and unifies heterogeneous public data into a single, consistent platform.
The system ingests data from multiple open registries, consolidates it into a unified data model, and enables fast search, filtering, and cross-linking between related entities while preserving data transparency and update history.
Product features
Multi-source open data aggregation
Automated ingestion of registry data for entrepreneurs, legal entities, and tenders/auctions from heterogeneous public sources.
Data normalization & unification
Transformation of inconsistent source structures into a unified data model optimized for search and analytical use cases.
Flexible document-based storage
A document-oriented storage approach using MongoDB to support evolving schemas and diverse registry formats without sacrificing consistency.
Entity profiles & relationships
Consolidated entity profiles with cross-linking between entrepreneurs, legal entities, and related tenders or auctions.
Fast search & filtering
Efficient querying and filtering across large datasets using optimized indexes.
Data freshness & provenance tracking
Update timestamps, change logs, and source attribution to ensure transparency and trustworthiness of the aggregated data.
Asynchronous ingestion & updates
Queue-based background workflows enabling independent ingestion, partial updates, and fault isolation across data sources.
Admin-friendly UI
Server-rendered interfaces for browsing, filtering, and inspecting aggregated data without heavy client-side complexity.
1. Source analysis & data mapping
Multiple public registries were analyzed to identify structural differences, update patterns, and data quality issues. A unified data model was designed to balance flexibility with consistency.
2. Ingestion architecture design
A queue-based ingestion pipeline was implemented, allowing independent processing of each source and minimizing the impact of partial failures.
3. Development & normalization
Normalization layers were introduced to unify fields, resolve inconsistencies, and establish relationships between entities across datasets. MongoDB was selected to support document-based modeling and schema evolution.
4. Stabilization & freshness control
Update tracking, change logging, and source attribution mechanisms were added to ensure long-term data reliability and transparency.
Result
The platform became a centralized, scalable foundation for working with public open data, enabling:
- A single source of truth across multiple registries
- Faster and more reliable search and cross-entity analysis
- Reduced manual effort in data reconciliation
- Improved transparency through data provenance and update history
- A flexible architecture ready for onboarding new data sources

Start creating something
exceptional together!
More recent Case Studies

Seamless LMS platform for interactive math education
A multi-tenant LMS platform for interactive arithmetic education that combines engaging, child-friendly learning experiences with structured learning flows and progress tracking. The system provides educational organizations with the tools to manage courses, classes, and users while maintaining full administrative control across multiple organizations.

Booking & E-commerce platform for beauty service providers
A booking and e-commerce platform built for real-world beauty service operations, combining reliable appointment scheduling with integrated product sales. The system ensures consistent availability, structured booking flows, and operational control while delivering a fast, mobile-friendly experience for clients.
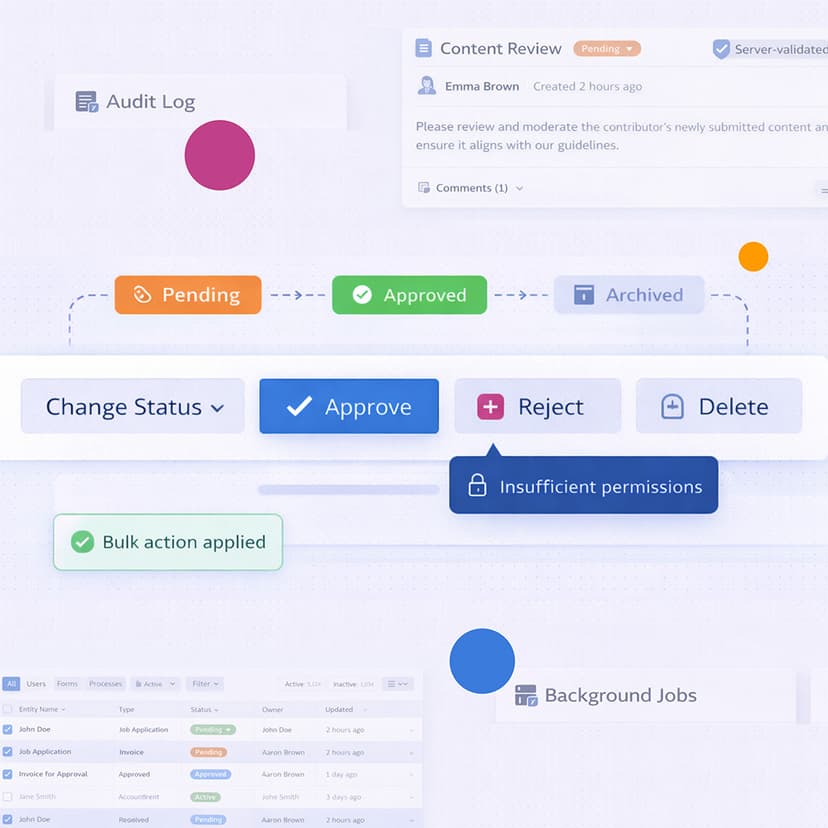
Admin Panels & Backoffice Suite for Internal Operations
A permission-driven admin and backoffice suite built for high-risk internal operations, where control, safety, and auditability are critical. The system enforces business rules server-side, supports role-based workflows, and provides clear visibility into actions, statuses, and execution history.
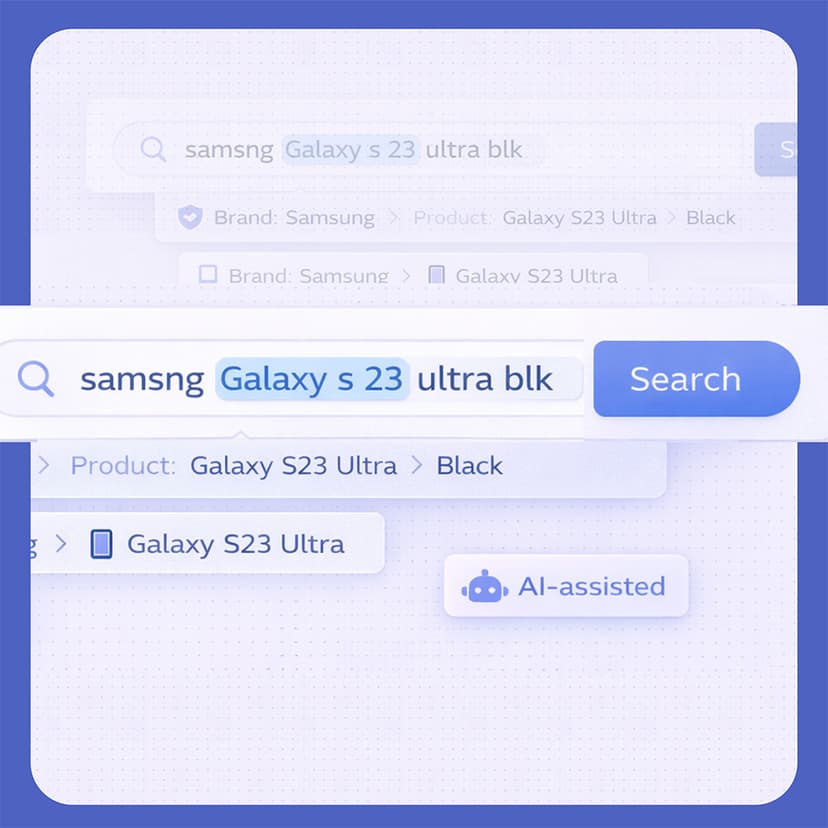
Smart Search System with AI-assisted Query Understanding
A smart search system built for real-world free-text queries, combining deterministic relevance modeling with AI-assisted query understanding. The solution handles typos, fuzzy matches, and mixed-language input while maintaining predictable behavior, stable relevance, and high performance at scale.
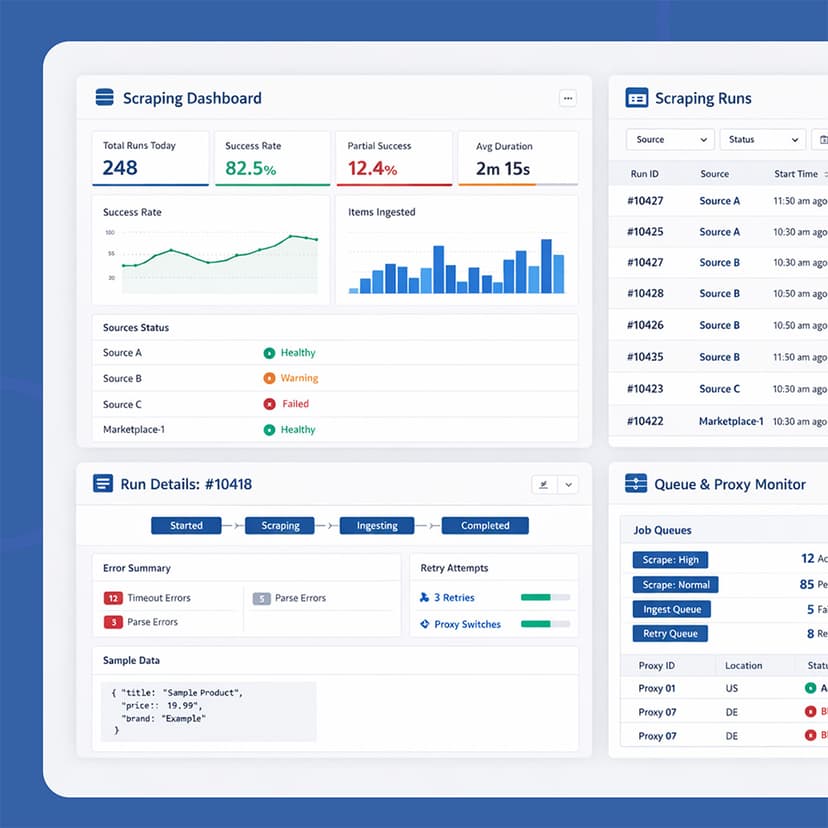
Retail Scraping & Ingestion System for E-commerce Data Collection
The system is designed for reliable extraction and ingestion of e-commerce product and promotional data. It supports multiple pagination strategies, operates through a managed proxy pool, and ensures stable data collection at scale. The goal is to provide consistent, observable, and fault-tolerant retail data pipelines.
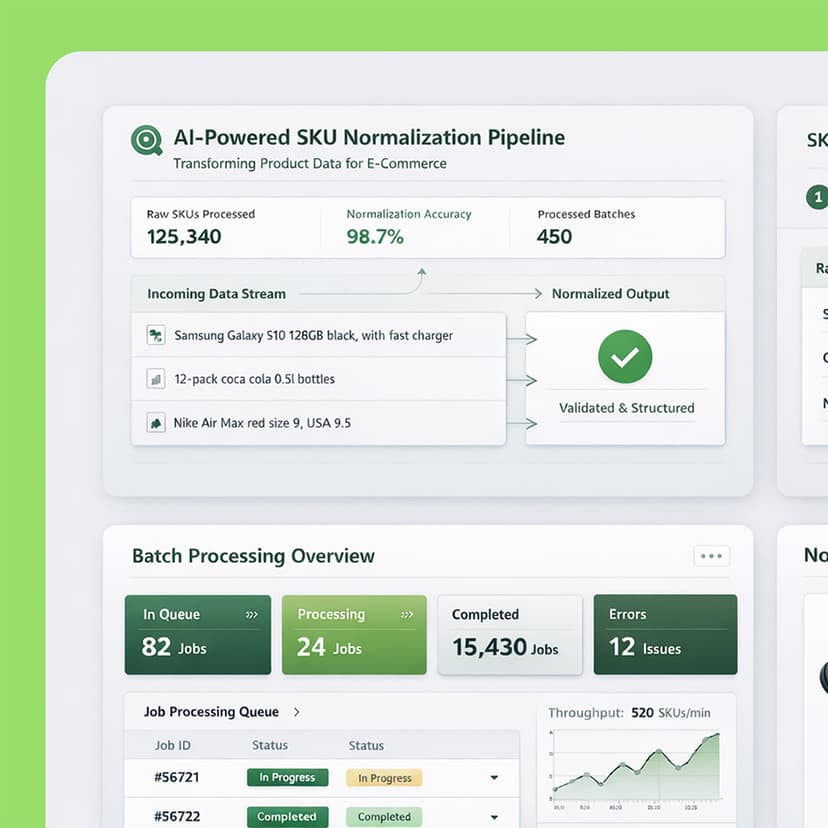
AI-powered SKU Normalization Pipeline for E-commerce Operations
The platform is designed to automatically normalize and standardize product data at scale. It transforms raw, inconsistent SKU titles and attributes into structured, high-quality product information, ensuring consistency across catalogs. The goal is to improve data accuracy, search relevance, and operational efficiency for e-commerce systems.
Custom SaaS CRM for E-commerce Operations
A custom SaaS CRM platform built for centralized order management, operational automation, and fulfillment workflows. The system integrates with WordPress-based e-commerce websites, synchronizes incoming orders, and helps operational teams manage the full order lifecycle from creation to shipment within a single platform.